問題描述
計算前綴和後陣列後,一旦更改某個值,則包含該值的前綴和都必須跟著改動。假設我們改動第 $2$ 格,則以後的前綴和都要改動,時間複雜度為 $O(n)$。因此我們試圖讓包含該值的區間可以減少,這樣就可以更動少一點資料。
Least Significant Bit(LSB)
在這裡的定義是最後面的 $1$ 所代表的數字
LSB 可以用以下方式計算:
- $x$ & $(-x)$
例如:
- $6$ 的二進位是 $110$,LSB = $2$
- $12$ 的二進位是 $1100$,LSB = $4$
- $24$ 的二進位是 $11000$,LSB = $8$
LSB 在 BIT 中扮演重要角色:
- 用來判斷每個節點負責的區間長度
- 用來找父節點和子節點
Binary Indexed Tree(BIT) 原理
BIT 利用二進位的特性,將每個位置負責不同長度的區間和。
這邊的 Binary 不是 Binary Tree,而是二進制的意思
例如 index = $6$ (二進位 $110$),則負責區間 $[5,6]$ 的和
- 因為 $6$ 的 LSB 是 $2$,所以往前負責 $2$ 個數字
圖解 BIT 結構
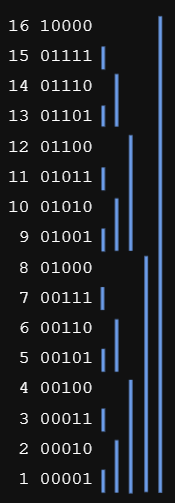 圖片來源:Ruby Ku 的投影片
圖片來源:Ruby Ku 的投影片
每個節點負責的區間長度就是它的 LSB,範圍為 $[i-LSB(i)+1, i]$。 例如:
- 節點 $8$ 的 LSB = $8$,負責 $[1,8]$
- 節點 $12$ 的 LSB = $4$,負責 $[9,12]$
- 節點 $14$ 的 LSB = $2$,負責 $[13,14]$
- 節點 $15$ 的 LSB = $1$,負責 $[15,15]$
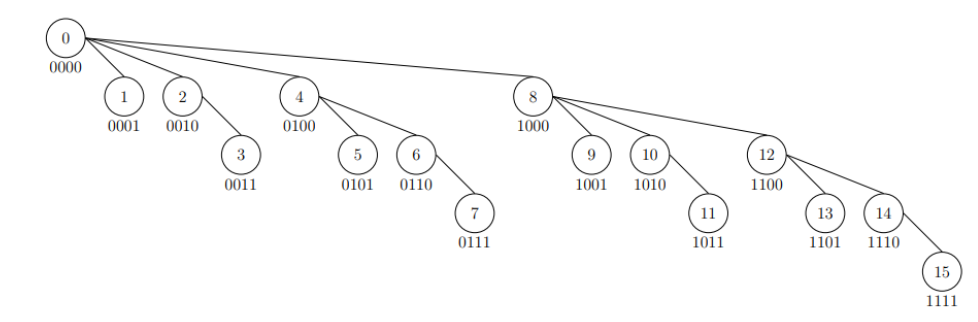 圖片來源:WIWIHO 的競程筆記
圖片來源:WIWIHO 的競程筆記
觀察此圖,我們可以發現:
- 節點 $0$ 是根節點
- 節點 $i$ 的父節點是 $i - LSB(i)$
- 節點 $i$ 的右兄弟節點是 $i + LSB(i)$。
- 若已經沒有右兄弟節點的話,$i + LSB(i)$ 會是 i 節點的父節點的右兄弟節點。可觀察第 $7$ 節點和第 $8$ 節點。
- 節點 $i$ 的深度與 $i$ 是 $1$ 的位元數相同
- 節點 $i$ 的父節點是 $p$,則節點 $i$ 的區間是 $[p+1, i]$,因為 $p = i - LSB(i)$
- 節點 $i$ 的區間包含它所有左兄弟節點的區間,因為它們的父節點都一樣,所以它們區間的起點都一樣,但 $i$ 的結束點較後面
- 節點 $i$ 的區間包含所有左兄弟節點 $j$ 的子孫節點的區間,因為 $j$ 子孫節點區間必在 $j$ 和 $i-1$ 之間,而 $i$ 的區間肯定包含這段。
實作細節
- update($x$, $val$):
- 更新 $x$ 位置的值,會影響到所有包含 $x$ 的區間
- 每次找右兄弟節點:$x$ += lowbit($x$)(第$3$點)
- 因為 x 的父節點的右兄弟也包含 x(第 $8$ 點),所以我要得到父節點的右節點,也就是最右兄弟節點為 $t$,其父節點的右兄弟就是 $t + LSB(t)$(第 $7$ 點)
void update(int x, int d){ // 把 x 節點的值改成 d
while(x <= N){
b[x] += d;
x += x & (-x);
}
}
可以發現 $LSB(x)$ 會不斷增加,所以複雜度是 $O(log n)$
- query($x$):
- 查詢以 $x$ 為結尾的的區間和,就要找到幾段不會重疊聯集為所求前綴的區間
- 區間以 $X$ 為結尾的節點是 ,而節點 $x$ 的區間剛好緊接在它的父節點之後,它的父節點是 $x - LSB(x)$,所以只要找到 $x$ 和它所有祖先節點,這些區間聯集起來就是我們想要的前綴
- 每次往上找父節點:$x$ -= lowbit($x$)
int query(int x){
int ret = 0;
while (x){
ret += b[x];
x -= x & (-x);
}
return ret;
}
同樣地, $LSB(x)$ 會不斷增加,因此複雜度是 $O(log n)$
- 建構 tree 時,如果有初始值的話,就把每一個元素分別 update 就好了,複雜度是 O(nlogn)
程式碼實作
#include <iostream>
#include <vector>
using namespace std;
const int N = 100005; // 根據需求調整大小
int bit[N]; // Binary Indexed Tree,1-based index
// 單點加值:將第 i 個位置加上 val
void update(int i, int val) {
while (i < N) {
bit[i] += val;
i += i & -i;
}
}
// 前綴和查詢:回傳前 i 個元素的總和
int query(int i) {
int res = 0;
while (i > 0) {
res += bit[i];
i -= i & -i;
}
return res;
}
// 查詢區間 [l, r] 的總和
int range_query(int l, int r) {
return query(r) - query(l - 1);
}
// 建表:從原始陣列 a[1..n] 建立 BIT
void build(const vector<int>& a, int n) {
for (int i = 1; i <= n; ++i) {
update(i, a[i]); // a 是從 1 開始的
}
}
int main() {
int n = 5;
vector<int> a(n + 1); // a[1..n]
a[1] = 3; a[2] = 2; a[3] = -1; a[4] = 6; a[5] = 5;
build(a, n); // 建立 BIT
cout << query(5) << "\n"; // 輸出 a[1] + ... + a[5]
cout << range_query(2, 4) << "\n"; // 輸出 a[2] + a[3] + a[4]
update(3, 4); // a[3] += 4
cout << query(5) << "\n"; // 查詢更新後的總和
return 0;
}
離散化 Discretization
處理元素值範圍太大或值不是連續整數(可能是浮點數或無序整數) 時常用的技巧。配合 BIT 就可以在這些情況下仍有效率地進行區間查詢。
假設要用 BIT 統計一個陣列中,小於某個值的元素有幾個。如果這些值範圍很大,例如 $10^9$,你就不能直接開一個長度 $10^9$ 的陣列來當 BIT,那會爆記憶體,所以我們要把這些值 壓縮成連續整數編號(例如 1、2、3…),來當作 BIT 的索引。
原始陣列:
vector<int> a = {100, 5000, 3, 100, 3};
- 提取所有值並排序
vector<int> vals = a;
sort(vals.begin(), vals.end());
vals.erase(unique(vals.begin(), vals.end()), vals.end()); // 移除重複值
- 建立「值 → 編號」的對應表
unordered_map<int, int> mp;
for (int i = 0; i < vals.size(); ++i) {
mp[vals[i]] = i + 1; // 使用 1-based index
}
- 用對應值更新 BIT
for (int x : a) {
int idx = mp[x]; // 取得離散化後的 index
update(idx, 1); // 假設你要統計出現次數
}
- 查詢小於某個值的個數(假設查小於 5000 的)
int idx = mp[5000]; // 5000 的 index
int res = query(idx - 1); // 查詢比它小的值的總出現次數
練習題
Zerojudge - d794. 世界排名
本題 AC code
- 3.5s, 22.4MB
#include <bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 100005;
int bit[N]; // Binary Indexed Tree,1-based
// 更新:將第 i 位加上 val
int update(int i, int val) {
while (i < N) {
bit[i] += val;
i += i & -i;
}
}
// 查詢:回傳前 i 位總和
int query(int i) {
int res = 0;
while (i > 0) {
res += bit[i];
i -= i & -i;
}
return res;
}
int main() {
int n;
while (cin >> n) {
for (int i = 1; i <= N; i++) {
bit[i] = 0; // clear BIT
}
vector<ll> a(n);
for (auto& x : a) {
cin >> x;
}
// Step 1: 離散化
vector<ll> vals = a;
sort(vals.begin(), vals.end());
vals.erase(unique(vals.begin(), vals.end()), vals.end());
unordered_map<ll, ll> mp; // 值 -> 離散後的 index(1-based)
for (int i = 0; i < vals.size(); ++i) {
mp[vals[i]] = i + 1;
}
// Step 2: 統計每個位置左邊比它小的數
for (int i = 0; i < n; ++i) {
int idx = mp[a[i]];
cout << i + 1 - query(idx - 1) << "\n"; // 查詢比當前值小的數有幾個
update(idx, 1); // 插入當前值進 BIT 中
}
}
return 0;
}
CSES - Nested Ranges Count
這題要求我們計算每個區間被多少其他區間包含,以及包含多少其他區間。
對於每個區間,我們需要輸出兩個數字
收集所有 $y$ 座標並離散化,方便作為 BIT 的 index
按照 $x$ 座標排序,如果 $x$ 座標相同,則按照 $y$ 座標降序排序
計算包含的區間數(當前區間為 $[a,b]$ 之前的區間為 $[c,d]$,$[a,b]$ 包含 $[c,d]$ 表示 $a<=c$ 且 $d<=b$)
- 從右至左處理,確保 $a <= c$
- 使用 BIT 記錄目前出現過的右界數量
- query($b$) 查詢目前已有的右界小於等於此區間右界($d<=b$)的總數量
計算被包含的區間數(當前區間為 $[a,b]$ 之前的區間為 $[c,d]$,$[a,b]$ 被 $[c,d]$ 包含表示 $a>=c$ 且 $b<=d$)
- 從左至右處理,確保 $a >= c$
- 透過「差分更新」的方法處理 BIT(對整體 $+1$,對 $b+1$ 開始 $-1$) 假設前兩個是 $[2,8]$, $[3,9]$,現在是 $[3,5]$
離散化後 ${5,8,9}$ -> ${1,2,3}$
這樣的話 $[2,8]$ 時會將 BIT[$2$] 以前的 BIT 都 $+1$
BIT[$1$] BIT[$2$] BIT[$3$] $1$ $1$ $0$ $[3,9]$ 時會將 BIT[$3$] 之前的 BIT 都 $+1$
BIT[$1$] BIT[$2$] BIT[$3$] $2$ $2$ $1$ 之後查 $[3,5]$ 時因為以確保左界會比之前的大,我們這時候查 query($1$),就可以得到之前有多少區間右界 $>=5$
本題 AC code
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define endl '\n'
#define F first
#define S second
map<int, int> mp;
const int N = 2e5 + 1;
int T[N + 1] = {0};
void update(int n, int x, int val) {
for (; x <= n; x += x & -x) T[x] += val;
}
int query(int x) {
int s = 0;
for (; x > 0; x -= x & -x) s += T[x];
return s;
}
bool comp(pair<pair<int, int>, int> a, pair<pair<int, int>, int> b) {
if (a.F.F == b.F.F) return a.F.S > b.F.S;
return a.F.F < b.F.F;
}
signed main() {
ios_base::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n;
cin >> n;
set<int> b;
vector<pair<pair<int, int>, int>> v(n);
for (int i = 0; i < n; i++) {
int x, y;
cin >> x >> y;
v[i].S = i;
v[i].F = {x, y};
b.insert(y);
}
int cnt = 0;
for (auto i : b) {
mp[i] = ++cnt;
}
sort(v.begin(), v.end(), comp);
update(cnt, mp[v[n - 1].F.S], 1);
int ans[n] = {0};
for (int i = n - 2; i >= 0; i--) {
ans[v[i].S] += query(mp[v[i].F.S]);
update(cnt, mp[v[i].F.S], 1);
}
for (int i = 0; i < n; i++) cout << ans[i] << ' ';
memset(ans, 0, sizeof ans);
memset(T, 0, sizeof T);
update(cnt, 1, 1);
update(cnt, mp[v[0].F.S] + 1, -1);
for (int i = 1; i < n; i++) {
ans[v[i].S] += query(mp[v[i].F.S]);
update(cnt, 1, 1);
update(cnt, mp[v[i].F.S] + 1, -1);
}
cout << endl;
for (int i = 0; i < n; i++) cout << ans[i] << ' ';
}